あなたのゲノムで備えよ 究極のデータ、倫理観問う
あなたのゲノムで備えよ 究極のデータ、倫理観問う
第1部 ブロックチェーンが変える未来(3)
米国ボストン。ハーバード大学の医学部の校舎が集まるロングウッドキャンパス。歴史を感じさせる重厚な校舎のなかで、ひときわ目立つ全面ガラス張りのビルが遺伝学部の校舎だ。フラスコやコンピューターが並ぶ研究室を通り抜けると、ジョージ・チャーチ教授のオフィスにたどり着く。
【関連記事】ゲノム 全遺伝情報が書き込まれた生命の「設計図」
チャーチ教授は、人の設計図とされるゲノム(全遺伝情報)の解析技術で世界に知られる。かつて30億ドル(約3300億円)かかった解析コストを数千ドルまで下げることに貢献してきた。ゲノム革命の立役者だ。

「人の5%は深刻な遺伝性疾患を持って生まれてくる。自分は残りの95%だと考えがちだが、それは事故に遭う可能性が低いと決めつけてシートベルトをしないのと同じだ。ゲノムを見てみないと分からない」。ゲノム解析で特定の病気を発症するリスクや薬剤への反応が事前に分かり、適切な予防策や治療を受けることができる。解析のコストは下がった。「なぜ備えないのか」。チャーチ教授は鋭い眼光で語る。
多くの人のゲノムを分析するほど、病気との関係が浮き彫りになる。チャーチ教授は2005年、医療研究を後押しする目的で任意の参加者のゲノムを解析し、ネット上で公開する「パーソナル・ゲノム・プロジェクト」を立ち上げた。ゲノムを解析する人がコスト低下とともに増え、病気の解明が進むと期待されていた。
ところが思惑とは違って、ゲノム解析を利用する人は少数にとどまっている。大きなハードルはプライバシーの問題だ。遺伝情報は究極の個人情報であることから、情報の漏洩や意図しない利用を懸念し、ゲノム解析サービスの利用や、研究や医療機関にデータを提供することをためらう消費者が多い。
現状を打開するのが、ブロックチェーン(分散型台帳)の活用だ。チャーチ教授は17年、研究員のデニス・グリシン氏と、米グーグルでブロックチェーン技術を担当していたカマル・オバド氏と、ネブラ・ゲノミクスを起業した。
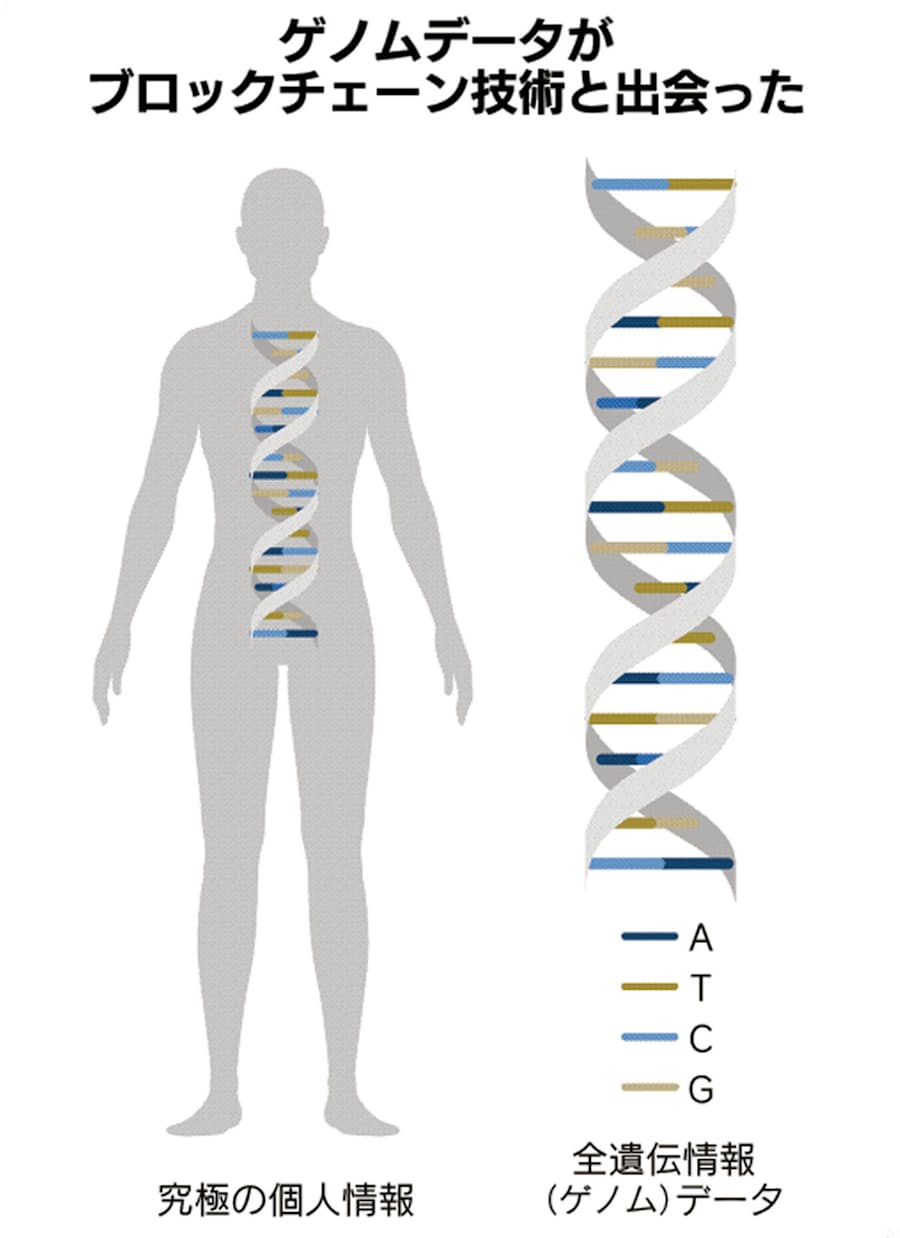
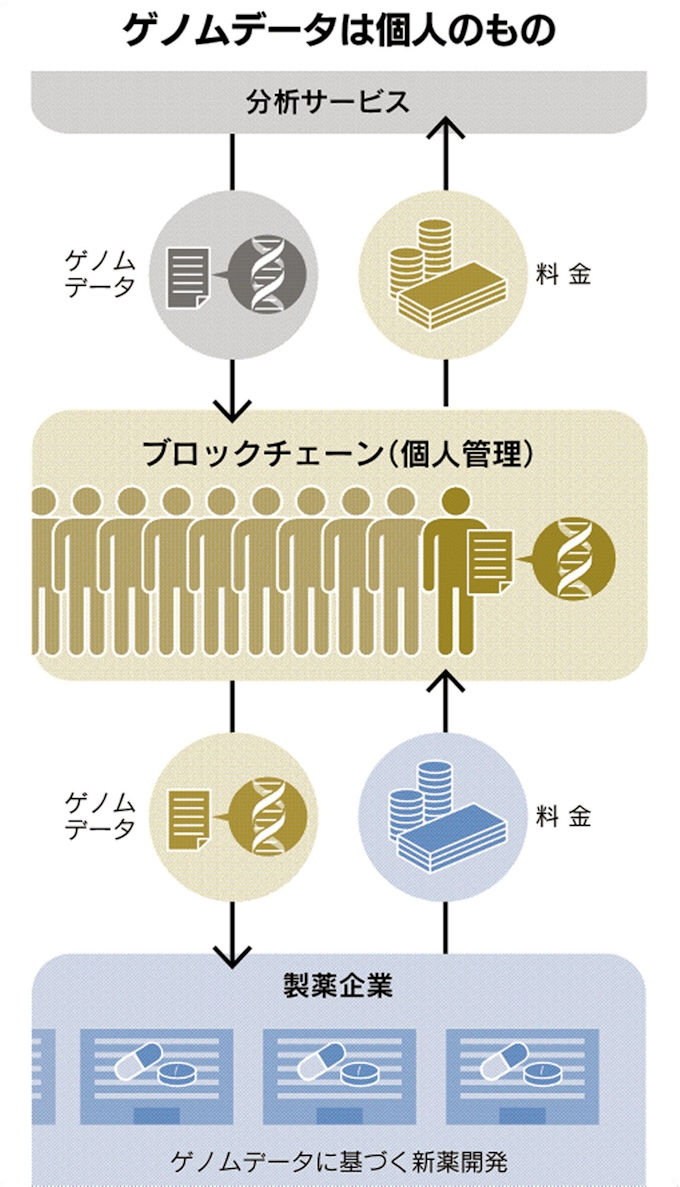
ブロックチェーンを使うことで、ゲノムデータのアクセス権限を管理したり、データがいつ誰によってどんな目的で使われたのかなどの履歴を常に確認したりできる。データが一人ひとりに分散していても共有しやすい。プライバシーを守りながら、やり取りできるのが強みだ。ネブラは「消費者自身が自分のデータを所有し、研究に使われるたびに本人に報酬が入る」ような未来図を描く。ゲノムデータに「価値」を持たせ、より多くの人にゲノム解析を促す。

ゲノム解析技術の発展により、ヒトのゲノムを構成する60億の文字(塩基)の配列うち、99%以上を解読できるようになった。一方、60億の塩基配列のうち、機能が分かっているのは1%に満たない。ネブラの共同創業者のグリシン氏は、ネブラを通して「多くのデータを生成し、研究者と共有することで医学の発展に貢献したい」と話す。
ネブラは、まずは消費者から受け取った唾液から全ゲノムを解析し、家系や身体的特徴、運動能力などの分析結果を消費者に提供する。今後は病気のリスクや薬物反応など医療応用につながるゲノム解析サービスも始める予定だ。将来は、ゲノムデータを研究に使いたいと考える製薬会社と消費者をつなぐ。製薬会社はデータにアクセスする一方で、解析のコストを負担する。参加者は無料で高精度の解析を受け、病状を改善できるようになると期待する。
チャーチ教授はゲノム解析サービスの普及プロセスは「インターネットサービスと似ている」と指摘する。「グーグルマップ」といったネット上の地図や情報サイトをみてもわかるように「サービスの提供にかかるコストが十分低くなれば、企業が自らコストを負担し、利用者は無料でサービスを利用できるようになる」と説明する。
人の体は37兆(37テラ)個の細胞からできており、1個ずつに60億(6ギガ)のゲノムデータが収まっている。人がゲノムという情報に価値を見いだしたとき、人体は自然界でいう「モノ」ではなく、「ビッグデータ」と見なせる。膨大なゲノムデータのやり取りが始まれば、医療や病気予防の姿はがらりと変わる。
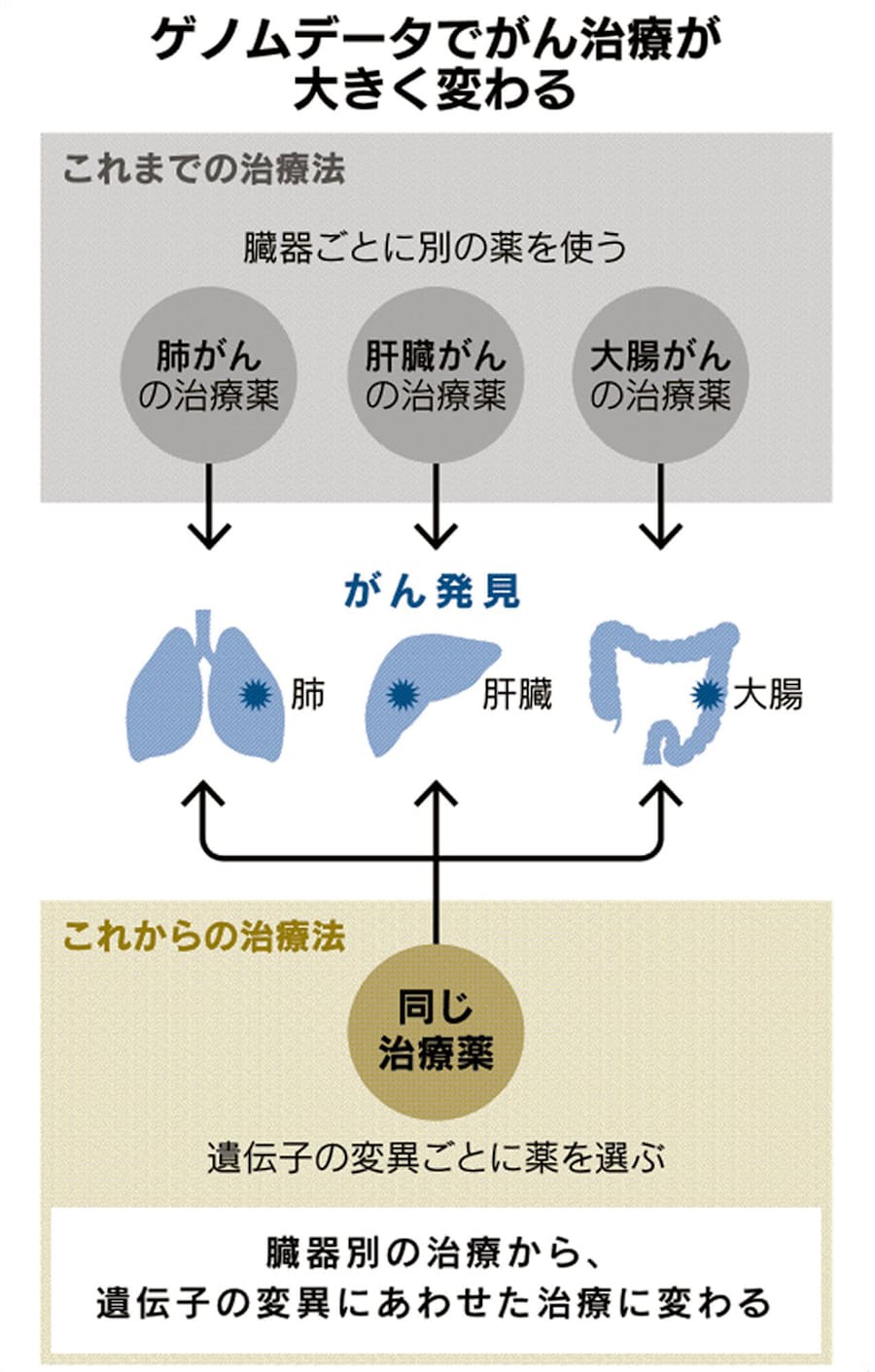
現代医学では、がんや認知症は一人ひとりのゲノムが環境要因と複雑に絡み合い、発症するとされる。10年単位で先を見通せば、ゲノムデータの活用が当たり前になっていく。国内ではこの春にもいくつかのがんを対象にゲノム医療が始まる。同じ病名でも患者のゲノムごとに治療法が異なる「パーソナル医療」の時代はすぐそこだ。
ゲノムデータは生まれたときから変わらない個人情報でもある。扱い方を誤れば人権を侵す。情報技術が爆発的な進化を遂げ、どんなデータもコピーされて瞬く間に世界へと拡散する。知らぬまに自分のコピー人間がつくられる、そんな空想科学(SF)小説の世界も現実味を帯びてくる。
同じ医療データでも、ゲノムデータは画像データや診療データと趣が違う。子どもや孫、親戚らと一部の情報が共有される性質があるからだ。国内でブロックチェーンを使ったヘルスケア改革を目指す国立保健医療科学院の水島洋・研究情報支援研究センター長も「(データ利用の)同意は本人だけではすまず、親戚一同も必要になる」と指摘する。
ゲノムデータはいったい誰のものか。個人主義の強い米国では自分のものという考えが一般的。一方、中国は国家のもので機密情報にあたるという。フランスやドイツのように遺伝子解析をビジネスとして認めない国もある。命に関わるデータを売って過当なお金を手にするとなれば、倫理面から批判がでるかもしれない。